
Cosa sono e come funzionano le API Graphics? Perché ad ARCore non piace Vulkan? Chi è più veloce, OpenGLES o Vulkan? Tutte queste ed altre curiosità in questo articolo.
Introduzione
Unity supporta le API (Application Programming Interface) grafiche DirectX, Metal, OpenGL e Vulkan, che utilizza o permette all’utente di sceglierle a seconda della disponibilità dell’API su una determinata piattaforma.
In questa fase introduttiva vedremo ad alto livello le varie API e CORE Grafici per mobile per capirne differenze e caratteristiche peculiari e terminando con il funzionamento di un Rendering Engine. Prima però è necessario spiegare alcuni concetti introduttivi.
CPU e GPU
Le CPU sono altamente specializzate nella velocità di calcolo e hanno una vasta gamma di istruzioni a basso livello. Le GPU sono invece più lente e più semplici, ma si concentrano sulla parallelizzazione (numero elevato di core) e hanno un set più limitato di istruzioni.
Mentre una CPU comune ha tra 2 e 16 core circa, una GPU in genere ha migliaia di core che eseguono operazioni in parallelo. Entrambe hanno una propria memoria indipendente e comunicano solo scambiando dati tramite un bus dedicato, a seconda dell’architettura.
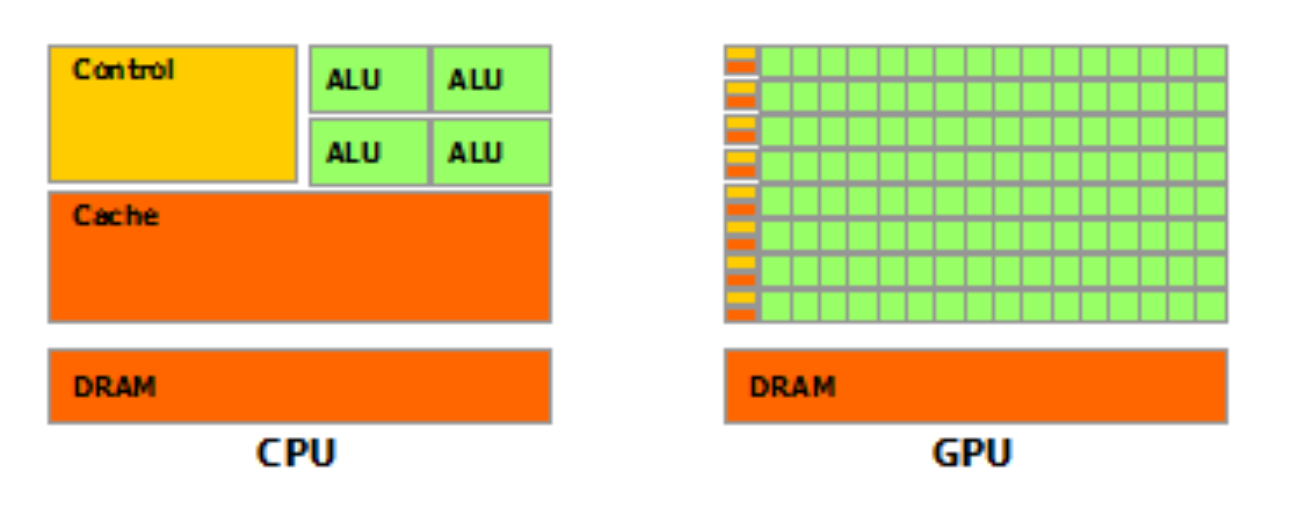 Le GPU dedicano la maggior parte dei loro transistor all’elaborazione dei dati, mentre le CPU necessitano di cache di grande dimensione, unità di controllo e così via.
I processori CPU funzionano secondo il principio di ridurre al minimo la latenza all’interno di ciascun thread mentre le GPU nascondono le istruzioni e le latenze di memoria con il calcolo.
Le GPU dedicano la maggior parte dei loro transistor all’elaborazione dei dati, mentre le CPU necessitano di cache di grande dimensione, unità di controllo e così via.
I processori CPU funzionano secondo il principio di ridurre al minimo la latenza all’interno di ciascun thread mentre le GPU nascondono le istruzioni e le latenze di memoria con il calcolo.
L’immagine di seguito mostra in proporzione, le differenze tra thread CPU e GPU.
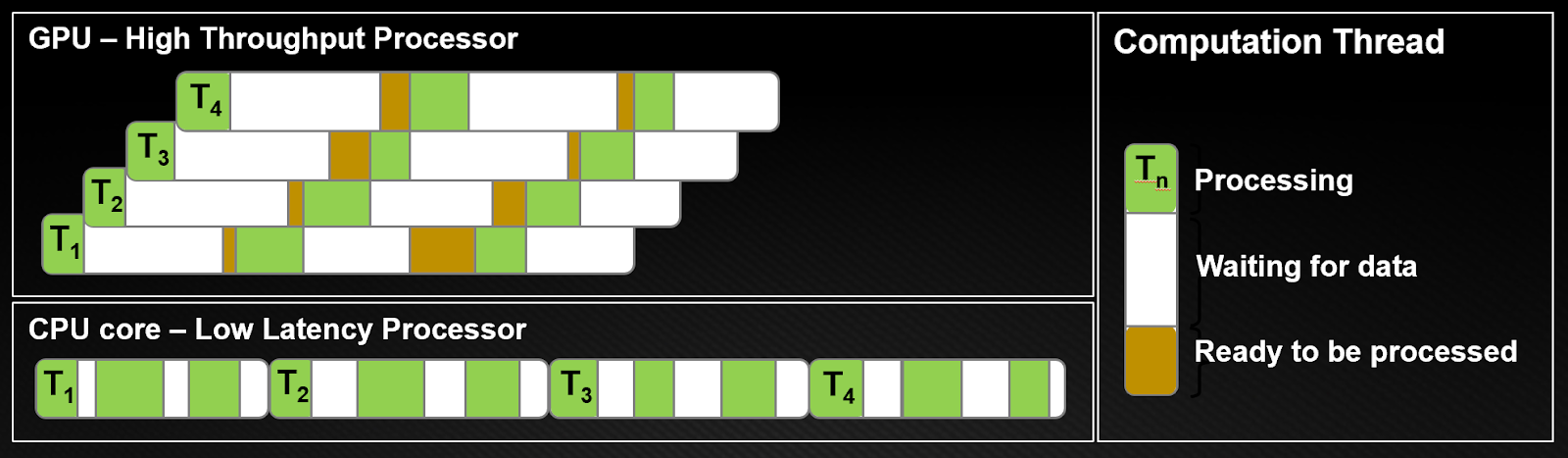
Le architetture CPU devono ridurre al minimo la latenza all’interno di ciascun thread. Sulle CPU, ogni thread riduce al minimo il tempo di accesso ai dati (barre bianche). Durante un singolo shot temporale, il segmento (barra verde) fa più lavoro possibile. Per raggiungere questo obiettivo, le CPU richiedono una bassa latenza, che richiede cache di grandi dimensioni e una logica di controllo complessa. Le cache funzionano meglio con pochi thread per core, poiché il cambio di contesto tra thread è oneroso e costoso.
Nelle GPU invece, i thread sono leggeri, quindi una GPU può passare da thread in stallo ad altri thread senza alcun costo con la stessa frequenza ad ogni ciclo di clock.
Come illustrato nella figura sopra, quando il thread T1 si blocca a causa di una richiesta di dati, un altro thread T2 iniziava l’elaborazione e così via con T3 e T4. Nel frattempo, T1 alla fine ottiene i dati da elaborare. In questo modo, la latenza si nasconde passando ad altri work da eseguire. Ciò significa che le GPU necessitano di molti thread simultanei sovrapposti per nascondere la latenza; quindi, avendo migliaia di thread piccoli da eseguire, la GPU è la migliore scelta.
GPGPU
Le GPGPU, sigla di general-purpose computing on graphics processing units (letteralmente “calcolo a scopo generale su unità di elaborazione grafica”), si intende l’uso di un’unità di elaborazione grafica (GPU) per scopi diversi dal tradizionale utilizzo nella grafica computerizzata.
In sostanza, una pipeline GPGPU è una sorta di elaborazione parallela tra una o più GPU e CPU che analizza i dati come se fossero in un’immagine o in altra forma grafica. Mentre le GPU funzionano a frequenze più basse, in genere hanno molte volte il numero di core. Pertanto, le GPU possono elaborare molte più immagini e dati grafici al secondo rispetto a una CPU tradizionale.
La migrazione dei dati in forma grafica e quindi l’utilizzo della GPU per scansionarli e analizzarli può creare una grande accelerazione.
OpenGL
OpenGL (Open Graphics Library) è un’interfaccia di programmazione multipiattaforma e applicativa che viene utilizzata per il rendering di grafica vettoriale in 2D e 3D.

OpenGL quindi non è un linguaggio di programmazione ma è un’API il cui scopo è quello in linea di massima è quello di portare i dati dalla CPU alla GPU. L’API è definita come un insieme di funzioni che possono essere chiamate dal programma client, insieme a un insieme di costanti intere.
Sebbene le definizioni delle funzioni siano superficialmente simili a quelle del linguaggio di programmazione C, sono indipendenti dal linguaggio. Come tale, OpenGL ha molti binding di linguaggio, il che rende l’API molto dinamica nel supporto di diverse piattaforme; alcuni dei più degni di nota sono JavaScript WebGL (API, basato su OpenGL ES 2.0, per il rendering 3D dall’interno di un browser web); C WGL, GLX e CGL; il vincolo C fornito da iOS; e Java e C per Android.
L’API OpenGL si compone di due parti:
- La libreria stessa, che è possibile utilizzare praticamente con qualsiasi linguaggio di programmazione. Questo è ciò che viene eseguito sulla CPU e invia istruzioni e dati alla GPU.
- Gli shader sono parti di istruzioni (codice) che vengono prima compilate dalla CPU, quindi inviate alla GPU. Questo è ciò che viene eseguito sul lato GPU. In OpenGL, gli shader vengono scritti utilizzando il linguaggio GLSL (Graphics Library Shading Language).
Le persone che sviluppano le librerie OpenGL effettive sono di solito i produttori di schede grafiche. Ogni scheda grafica acquistata supporta versioni specifiche di OpenGL che sono le versioni di OpenGL sviluppate appositamente per quella scheda (o per una serie di schede). Quando si utilizza un sistema Apple, la libreria OpenGL è gestita da Apple stessa e sotto Linux esiste una combinazione di versioni di fornitori e adattamenti di queste librerie da parte di sviluppatori di terze parti. Ciò significa anche che ogni volta che OpenGL mostra un comportamento strano che non dovrebbe, è molto probabilmente colpa dei produttori di schede grafiche (o di chiunque abbia sviluppato / mantenuto la libreria).
OpenGLES
OpenGL for Embedded Systems(OpenGLES o GLES) è un sottoinsieme dell’API per il rendering 2D e 3D di computer grafica 2D e 3D come quelle utilizzate dai videogiochi, tipicamente accelerate dall’hardware utilizzando un’unità di elaborazione grafica (GPU). È progettato per sistemi embedded come smartphone, tablet, console per videogiochi e PDA.
OpenGLES è l’API grafica 3D più diffusa nella storia.
![]()
OpenGL e OpenCL non sono la stessa cosa
A volte si fa confusione tra OpenGL e OpenCL, che sono due cose diverse. OpenGL, come abbiamo visto sopra, è un’interfaccia di programmazione multipiattaforma che viene utilizzata per il rendering di grafica vettoriale in 2D e 3D. OpenCL (Open Computing language) è un framework che viene utilizzato per creare un programma per il calcolo su piattaforme eterogenee.
Vulkan
Vulkan è un’API grafica e di elaborazione di nuova generazione che fornisce un accesso multipiattaforma ad alta efficienza alle moderne GPU utilizzate in un’ampia varietà di dispositivi, da PC e console a telefoni cellulari e piattaforme embedded.
Vulkan non è un’azienda, né un linguaggio, ma piuttosto un modo per gli sviluppatori di programmare il loro moderno hardware GPU in modo multipiattaforma e cross-vendor. Il Gruppo Khronos è un consorzio guidato dai membri che ha creato e mantiene Vulkan.
Prima di descrivere il funzionamento di Vulkan e le differenze con OpenGLES è necessario capire come funziona un rendering engine…
Come funziona un Rendering Engine
Partiamo dal principio. Uno sviluppatore grafico utilizza l’API grafica per inviare dati dalla CPU alla GPU. Una volta che i dati raggiungono la GPU passano attraverso la pipeline di rendering e gli elementi grafici vengono elaborati e prendono vita.
Per far questo la GPU riceve un set di dati, formato da:
- Attributes - vengono utilizzati dalla GPU per assemblare una geometria, applicare luci e immagini ad elemento del gioco. Alcuni attributi sono la posizione dei vertici (utilizzate dalla GPU per assemblare la geometria dell’elemento) e le coordinate normali (sono vettori perpendicolari a una superficie e vengono utilizzati per applicare la luce ad un elemento) e le coordinate U-V (utilizzate per mappare un’immagine al carattere).
- Uniforms - Le uniforms forniscono dati spaziali alla GPU. Questi dati spaziali informano la GPU su dove posizionare un personaggio di gioco rispetto allo schermo.
- Texture - Una texture è un’immagine 2D che viene utilizzata per avvolgere un personaggio.
Il set di dati arriva alla GPU, dove viene elaborato tramite alcune componenti interne alla GPU dette shader. Uno shader è un programma che vive nella GPU. Gli shader sono programmabili e consentono la manipolazione della geometria e del colore dei pixel. Nella GPU sono presenti i seguenti shader:
- Vertex Shader
- Fragment Shader
- Tessellation Shader
- Geometry Shader
Una volta che i dati sono nella GPU, vengono elaborati dalla pipeline di rendering OpenGL.
OpenGL Rendering Pipeline
La pipeline di rendering elabora i dati attraverso diverse fasi note come:

Vertex Specification
Questo processo imposta un elenco ordinato di vertici da inviare alla pipeline. I vertici da inviare alla pipeline deviniscono i confini di una primitiva e passate in input alla fase successiva..
Cos’è una primitiva? Le primitive sono forme di disegno base come triangoli, linee e punti.
Vertex Processing
Ogni vertice, dato da una matrice di vertici, viene utilizzato da un Vertex Shader.
Un Vertex Shader è lo stadio programmabile nella pipeline di rendering che gestisce l’elaborazione dei singoli vertici; riceve un singolo vertice composto da una serie di attributi riferiti al vertice stesso. Questo vertice di input viene elaborato per produrre un insieme di vertici di output secondo una mappatura 1:1.
La fase successiva è quella di Tessellation: Questo step prende in input i vertici in uscita dallo stadio precedente, li raccoglie in primitive e li tassella nelle medesime primitive (questa fase è facoltativa).
L’ultima fase del primo processo è la Geometry Shader che gestisce l’elaborazione delle primitive, producendo una sequenza di vertici che genera 0 o più primitive (questa fase è facoltativa).

Vertex post-processing & Primitive Assembly
Dopo l’elaborazione basata su shader, i vertici subiscono una serie di fasi di elaborazione.
La prima fase del post-processing è la Primitive Assembly, in questa fase vengono raccolti i dati sui vertici risultanti dalle fasi precedenti e viene effettuata una composizione in una sequenza di primitive.
Il risultato di questo processo è una sequenza ordinata di primitive semplici (linee, punti o triangoli).
Ad esempio, se l’input di questo processo è una primitiva a striscia triangolare contenente 12 vertici, l’output di questo processo sarà di 10 triangoli.
In seguito queste primitive subiscono il processo di Clipping, cioè le primitive che si trovano al confine tra l’interno e l’esterno sono divise in diverse primitive in modo che la primitiva interna si trovi all’interno del volume della primitiva esterna (Ad esempio, in un triangolo potrei collegare il punto che si trova sulla base del triangolo con il vertice superiore).
L’ultima fase è la Face culling, dove le primitive del triangolo possono essere eliminate (ad esempio scartate senza rendering), in base alla faccia del triangolo nello spazio della finesta. Questo significa che per le superfici chiuse, questi triangoli sarebbero coperti dai triangoli rivolti verso l’utente e quindi non saranno mai rendereizzati.
Rasterization
In questo stadio le primitive in input vengono rasterizzate nell’ordine di input, questa fase produce in output una sequenza di Fragment.
Un Fragment è un insieme di stati utilizzato per calcolare i dati finali per un pixel nel frame buffer di output.
Lo stato di un frammento contiene alcune informazioni, tra cui la sua posizione nello schermo, la copertura dell’elemento, ecc.
Fragment Processing
I dati di ogni fragment vengono elaborati dal Fragment Shader. L’output di questa fase è un elenco di colori per ciascuno dei buffer di colore in cui viene scritto, un valore di profondità e un valore di stencil.
Per-Sample Operations
L’output dei dati di fragment subiscono ora una serie di test. Il primo passo è una sequenza di test di abbattimento; se un test è positivo e il frammento non supera il test, i pixel/campioni sottostanti non vengono aggiornati (di solito).
Dopo questi test, avviene la fusione dei colori. Per ogni valore di colore del fragment, esiste un’operazione di fusione specifica tra esso e il colore già presente nel framebuffer in quella data posizione.
Le operazioni logiche possono anche essere eseguite al posto della fusione, che esegue operazioni bit per bit tra i colori del frammento e i colori del framebuffer.
Infine, i dati del frammento vengono scritti nel framebuffer.
OpenGLES vs Vulkan in Unity
Vulkan non è un concorrente diretto di OpenGL, dato che è lo stesso consorzio Khronos a gestire entrambe, ma piuttosto un’API che consente un controllo più esplicito della GPU.
Ad esempio per uno sviluppo mobile Android le due API grafiche sono OpenGLES e Vulkan.
Chi è più veloce ed efficiente? Dipende…
State Management
OpenGL ES utilizza un singolo stato globale e deve ricreare le tabelle di binding dello stato di rendering e delle risorse necessarie per ogni chiamata di paint effettuata. Le combinazioni di stati utilizzate sono note solo al momento del painting, il che significa che alcune ottimizzazioni sono difficili e costose da applicare.
Vulkan utilizza stati basati su oggetti, noti come descriptors, consentendo all’applicazione di preconfezionare in anticipo combinazioni di stati utilizzati. Gli oggetti pipeline compilati combinano tutti gli stati rilevanti, consentendo di applicare ottimizzazioni basate su shader in modo più prevedibile per ridurre i costi di runtime.
API execution model
OpenGL ES utilizza un modello di rendering sincrono, il che significa che una chiamata API deve comportarsi come se tutte le chiamate API precedenti fossero già state elaborate. In realtà nessuna GPU moderna funziona in questo modo, i carichi di lavoro di rendering vengono elaborati in modo asincrono e il modello sincrono è un’illusione elaborata mantenuta dal driver del dispositivo. Per mantenere questa illusione, il driver deve tenere traccia delle risorse lette o scritte da ogni operazione di rendering nella coda, assicurarsi che i carichi di lavoro vengano eseguiti in un ordine corretto per evitare il danneggiamento del rendering e garantire che le chiamate API richiedano un blocco delle risorse di dati e attendere fino a quando tali risorse non sono disponibili in modo sicuro.
Vulkan utilizza un modello di rendering asincrono, che riflette il funzionamento delle moderne GPU. Le applicazioni mettono in coda i comandi di rendering, utilizzano dipendenze di pianificazione esplicite per controllare l’ordine di esecuzione del carico di lavoro e utilizzano primitive di sincronizzazione esplicite per allineare l’elaborazione CPU e GPU dipendente.
L’impatto di queste modifiche è quello di ridurre significativamente il sovraccarico della CPU dei driver di grafica, richiedendo all’applicazione di garantire la gestione delle dipendenze e la sincronizzazione.
API threading model
OpenGL ES utilizza un modello di rendering a singolo thread, che limita fortemente la capacità di un’applicazione di utilizzare più core CPU nella pipeline di rendering principale.
Vulkan utilizza un modello di rendering multi-thread, che consente a un’applicazione di parallelizzare le operazioni di rendering su più core della CPU.
API error checking
OpenGL ES è un’API strettamente specificata con un ampio controllo degli errori di runtime. Molti errori derivano da errori di programmazione che si verificano solo durante lo sviluppo e che non possono essere gestiti in modo utile in fase di esecuzione, ma il controllo in fase di esecuzione deve comunque verificarsi, il che aumenta il sovraccarico del driver nelle build di rilascio di tutte le applicazioni.
Vulkan è strettamente specificato dalla specifica di base, ma non richiede al driver di implementare il controllo degli errori di runtime. L’uso non valido dell’API può causare il danneggiamento del rendering o addirittura arrestare l’applicazione in modo anomalo. In alternativa al controllo degli errori sempre attivo, Vulkan fornisce un framework che consente di inserire driver di livello tra l’applicazione e il driver Vulkan nativo. Questi livelli possono implementare il controllo degli errori e altre funzionalità di debug e hanno il vantaggio principale di poter essere rimossi quando non necessari.
Render pass abstraction
L’API OpenGL ES non ha alcun principo di gestione degli oggetti di passaggio sul rendering, ma è fondamentale per la funzione di base di un renderer basato su riquadri. Il driver grafico deve quindi dedurre quali comandi di rendering formano un singolo passaggio al volo, un compito che richiede un certo tempo di elaborazione e si basa su euristiche che possono essere imprecise.
L’API Vulkan è costruita attorno al concetto di passaggi di rendering e include inoltre il concetto di sottopassaggio all’interno di un singolo passaggio che può essere tradotto automaticamente in operazioni di ombreggiatura in-tile in un renderer basato su tile. Questa codifica esplicita elimina la necessità di utilizzare euristiche e riduce ulteriormente il carico del driver poiché le strutture di passaggio di rendering possono essere costruite in anticipo.
Memory allocation
OpenGLES utilizza un modello di memoria client-server. Questo modello delimita esplicitamente le risorse accessibili sul client (CPU) e sul server (GPU) e fornisce funzioni di trasferimento che spostano i dati tra i due processori. Questo ha due principali effetti collaterali:
In primo luogo, l’applicazione non può allocare o gestire direttamente la memoria che supporta le risorse lato server. Il driver gestirà tutte queste risorse individualmente utilizzando allocatori di memoria interni, inconsapevoli di eventuali relazioni di livello superiore che potrebbero essere sfruttate per ridurre i costi. In secondo luogo c’è un costo di sincronizzazione delle risorse tra client e server, in particolare nei casi in cui vi è un conflitto tra il requisito di rendering sincrono dell’API e la realtà di elaborazione asincrona.
Vulkan è progettato per l’hardware moderno e presuppone un certo livello di coerenza della memoria supportata dall’hardware tra la CPU e il dispositivo di memoria visibile dalla GPU. Ciò consente all’API di fornire all’applicazione un controllo più diretto sulle risorse di memoria, su come vengono allocate e su come vengono aggiornate. Il supporto della coerenza della memoria consente ai buffer di rimanere mappati in modo persistente nello spazio degli indirizzi dell’applicazione, evitando il ciclo continuo map-unmap che OpenGL ES richiede per iniettare operazioni manuali di coerenza.
Vulkan è migliore?
Vulkan è un’API di basso livello che dà all’applicazione molta potenza per ottimizzare le cose, ma in cambio spinge anche molta responsabilità sull’applicazione per fare le cose nel modo giusto. La cosa più importante da ricordare è che Vulkan non darà necessariamente un aumento delle prestazioni.
Vantaggi
Il più grande vantaggio che Vulkan porta è il carico ridotto della CPU nei driver e nella logica di rendering delle applicazioni. Ciò si ottiene attraverso la semplificazione dell’interfaccia API e la capacità di multi-thread dell’applicazione. Ciò può aumentare le prestazioni per le applicazioni con CPU limitata e migliorare l’efficienza energetica complessiva del sistema.
Il secondo vantaggio è una riduzione dei requisiti di ingombro di memoria di un’applicazione, grazie al riciclaggio intra-frame delle risorse di memoria intermedie. Mentre questo è raramente un problema nei dispositivi di fascia alta, può consentire nuovi casi d’uso nei dispositivi del mercato di massa con RAM più piccole collegate.
Svantaggi
Lo svantaggio principale di Vulkan è che spinge molte responsabilità sull’applicazione, tra cui l’allocazione della memoria, la gestione delle dipendenze del carico di lavoro e la sincronizzazione CPU-GPU. Mentre questo consente un alto grado di controllo e messa a punto, aggiunge anche il rischio che l’applicazione faccia qualcosa di non ottimale e perda prestazioni.
Vale anche la pena notare che livello più basso di astrazione significa che Vulkan può essere più sensibile alle differenze nell’hardware GPU sottostante, riducendo la portabilità delle prestazioni perché i driver non possono aiutare a nascondere le differenze hardware. Ad esempio, le dipendenze OpenGLES sono interamente consegnate alla gestione del driver del dispositivo mentre per Vulkan sono controllate dall’applicazione. Ci sono dipendenze di rendering che funzioneranno bene su un renderer tradizionale in modalità immediata che sono troppo conservative per un renderer di base tile, e quindi causano colli di bottiglia e alcune parti della GPU rimangono inattive.
Ma perché ad ARCore non piace Vulkan?
Quando proviamo ad utilizzare un progetto Unity con ARCore e API Grafica Vulkan appare un errore nella console Unity. Questo perché banalmente ARCore non supporta l’utilizzo con Vulkan, nei capitoli precedenti è stato descritto come Vulkan richieda una gestione della GPU con maggiori responsabilità lato applicativo rispetto OpenGLES che invece le pone lato driver.
Fonti
- Documentazione Unity - Graphics API support;
- Introduction to GPUs with OpenGL;
- OpenGL Overview;
- OpenGL ES Wikipedia;
- How does a Rendering Engine work? An overview;
- KhronosGroup - Vulkan-Guide;
- KhronosGroup - Vulkan-Guide;
- How does a Rendering Engine work? An overview;
- Rendering Pipeline Overview;
Articoli e video consigliati per approfondimento
- How does a Rendering Engine work? An overview;
- Vulkan vs OpenGL;
- Confronto tecnico OpenGLES vs Vulkan;
Grazie ☺